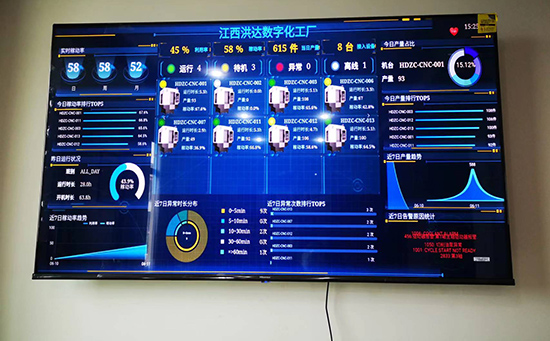
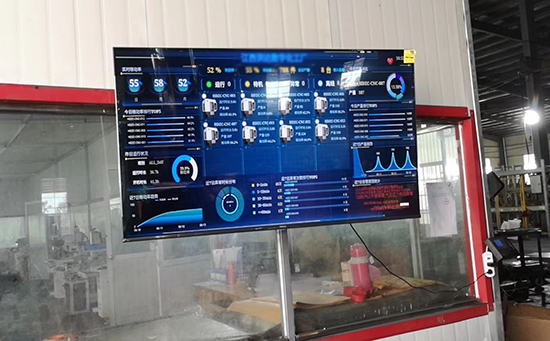
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬用戶實(shí)施案例,ERP 系統(tǒng)實(shí)現(xiàn)微信、銷售、庫存、生產(chǎn)、財(cái)務(wù)、人資、辦公等一體化管理
在處理文本匹配時(shí),`if`函數(shù)是編程中常用的一種條件判斷方法。在很多編程語言中,`if`語句被用來根據(jù)給定條件執(zhí)行不同的操作。當(dāng)涉及到文本匹配時(shí),`if`語句的使用尤為重要,它能夠幫助開發(fā)者根據(jù)字符串是否符合某一模式來決定執(zhí)行的動(dòng)作。本文將詳細(xì)介紹如何在`if`函數(shù)中進(jìn)行文本匹配,探討常見的文本匹配方法以及一些優(yōu)化技巧。
文本匹配的基本概念
文本匹配是指將一個(gè)給定的字符串與另一個(gè)目標(biāo)字符串進(jìn)行比對(duì),看是否符合某一特定的規(guī)則或模式。在許多編程語言中,`if`語句是實(shí)現(xiàn)文本匹配的基本工具之一。通過條件表達(dá)式,開發(fā)者可以確定某個(gè)字符串是否符合預(yù)期,并基于此結(jié)果執(zhí)行特定的代碼塊。
在實(shí)際應(yīng)用中,文本匹配不僅限于檢查兩個(gè)字符串是否完全相同,還可能涉及到部分匹配、正則表達(dá)式匹配等復(fù)雜的情況。正確使用`if`語句,結(jié)合文本匹配的不同技術(shù),可以大大提高程序的效率和準(zhǔn)確性。
常見的文本匹配方法
在不同的編程語言中,處理文本匹配的方式有所不同,但基本的思路是一樣的。以下是幾種常見的文本匹配方法:
1. 完全匹配
完全匹配是指判斷兩個(gè)字符串是否一模一樣。在許多編程語言中,`if`語句可以直接通過等號(hào)(`==`)來實(shí)現(xiàn)這個(gè)功能。例如:
“`python
if string1 == string2:
print(“字符串匹配”)
“`
這種方法適用于需要判斷兩個(gè)字符串是否完全相等的場(chǎng)景。它簡單且高效,但只能處理最基本的匹配需求。
2. 部分匹配
部分匹配是指判斷一個(gè)字符串是否包含另一個(gè)字符串。這通常用于檢查某些特定的詞或字符是否出現(xiàn)在目標(biāo)字符串中。例如,在Python中,可以使用`in`操作符來進(jìn)行部分匹配:
“`python
if substring in fullstring:
print(“子串匹配”)
“`
這種方法非常適合用來查找某個(gè)特定的詞或字符,并且能夠簡潔地表達(dá)出判斷邏輯。
3. 正則表達(dá)式匹配
正則表達(dá)式是一種強(qiáng)大的文本匹配工具,它允許開發(fā)者通過復(fù)雜的模式來匹配字符串。許多編程語言(如Python、JavaScript等)都支持正則表達(dá)式。在`if`語句中,正則表達(dá)式可以與文本匹配方法結(jié)合使用,從而進(jìn)行更復(fù)雜的文本判斷。
例如,在Python中,使用`re`模塊來進(jìn)行正則表達(dá)式匹配:
“`python
import re
if re.match(r”\d+”, string):
print(“字符串是數(shù)字”)
“`
正則表達(dá)式使得開發(fā)者能夠匹配各種復(fù)雜的模式,如數(shù)字、字母、日期等。
4. 大小寫匹配
在很多情況下,文本匹配需要忽略字母的大小寫。為了實(shí)現(xiàn)這一點(diǎn),通常可以先將字符串轉(zhuǎn)換為統(tǒng)一的大小寫,然后再進(jìn)行匹配。比如,在Python中,可以使用`lower()`方法將字符串轉(zhuǎn)換為小寫,再進(jìn)行比較:
“`python
if string1.lower() == string2.lower():
print(“大小寫不敏感的字符串匹配”)
“`
這種方法適用于不關(guān)心字符大小寫的文本匹配需求。
文本匹配中的`if`語句應(yīng)用實(shí)例
在實(shí)際開發(fā)中,`if`語句的應(yīng)用場(chǎng)景十分廣泛。以下是一些典型的應(yīng)用實(shí)例:
1. 驗(yàn)證用戶輸入
在用戶輸入文本時(shí),我們常常需要驗(yàn)證用戶輸入是否符合某種格式,如郵箱地址、手機(jī)號(hào)等。通過`if`語句配合文本匹配方法,可以輕松實(shí)現(xiàn)這種驗(yàn)證功能。
“`python
import re
user_input = input(“請(qǐng)輸入郵箱地址:”)
if re.match(r”[^@]+@[^@]+\.[^@]+”, user_input):
print(“郵箱地址格式正確”)
else:
print(“郵箱地址格式不正確”)
“`
該代碼段通過正則表達(dá)式驗(yàn)證郵箱地址的格式,若輸入的郵箱地址符合正則規(guī)則,則通過`if`語句執(zhí)行相關(guān)操作。
2. 搜索功能
在一些應(yīng)用程序中,用戶可以通過輸入關(guān)鍵詞來搜索信息。此時(shí),文本匹配是實(shí)現(xiàn)搜索功能的核心。我們可以利用`if`語句結(jié)合部分匹配來實(shí)現(xiàn)簡單的搜索功能。
“`python
data = [“蘋果”, “香蕉”, “橙子”]
search = input(“請(qǐng)輸入要搜索的水果:”)
if search in data:
print(f”找到了: {search}”)
else:
print(“未找到相關(guān)水果”)
“`
該示例展示了如何利用`if`語句判斷用戶輸入的水果是否在數(shù)據(jù)列表中,并返回相應(yīng)的搜索結(jié)果。
3. 處理不同類型的輸入
有時(shí)程序需要根據(jù)用戶的輸入類型(如文本、數(shù)字等)執(zhí)行不同的操作。通過`if`語句配合文本匹配方法,可以輕松實(shí)現(xiàn)類型識(shí)別。
“`python
user_input = input(“請(qǐng)輸入內(nèi)容:”)
if user_input.isdigit():
print(“您輸入的是數(shù)字”)
elif user_input.isalpha():
print(“您輸入的是字母”)
else:
print(“輸入包含了非字母和數(shù)字的字符”)
“`
在這個(gè)例子中,`if`語句用于判斷用戶輸入的內(nèi)容是否為純數(shù)字或純字母,從而決定執(zhí)行的操作。
優(yōu)化文本匹配的技巧
雖然`if`語句是文本匹配的基礎(chǔ)工具,但在處理大規(guī)模數(shù)據(jù)或復(fù)雜匹配時(shí),效率可能成為一個(gè)問題。以下是一些優(yōu)化技巧:
1. 使用編譯后的正則表達(dá)式
在進(jìn)行正則表達(dá)式匹配時(shí),反復(fù)編譯正則表達(dá)式會(huì)增加額外的開銷。為提高效率,建議在程序開始時(shí)編譯正則表達(dá)式,并在后續(xù)的匹配中復(fù)用:
“`python
import re
pattern = re.compile(r”\d+”)
if pattern.match(string):
print(“匹配成功”)
“`
2. 利用字典加速查找
對(duì)于一些常見的文本匹配,可以將目標(biāo)字符串預(yù)先存儲(chǔ)在字典中,然后通過字典加速匹配過程。例如,在查找大量關(guān)鍵詞時(shí),字典的查找效率遠(yuǎn)高于線性遍歷列表。
3. 避免重復(fù)的字符串轉(zhuǎn)換
在文本匹配中,避免對(duì)字符串進(jìn)行多次轉(zhuǎn)換(如多次轉(zhuǎn)換為小寫或大寫)。可以將字符串轉(zhuǎn)換的操作集中到一個(gè)步驟中,從而減少重復(fù)計(jì)算。
總結(jié)
在編程中,`if`語句是進(jìn)行文本匹配的常見工具之一。通過合理運(yùn)用完全匹配、部分匹配、正則表達(dá)式匹配等方法,可以實(shí)現(xiàn)不同需求的文本判斷。掌握這些技術(shù),并結(jié)合實(shí)際場(chǎng)景優(yōu)化匹配效率,對(duì)于提升程序性能和用戶體驗(yàn)至關(guān)重要。通過本文的介紹,開發(fā)者可以更好地理解和應(yīng)用`if`語句進(jìn)行文本匹配,并根據(jù)實(shí)際需求選擇最合適的匹配方法。