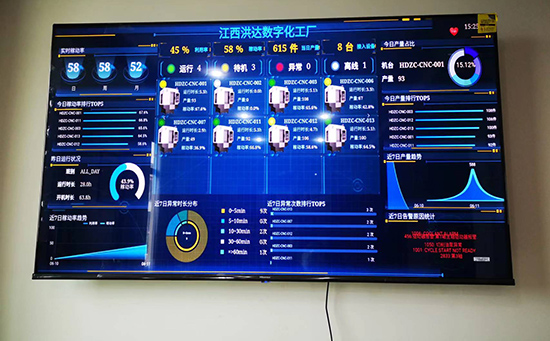
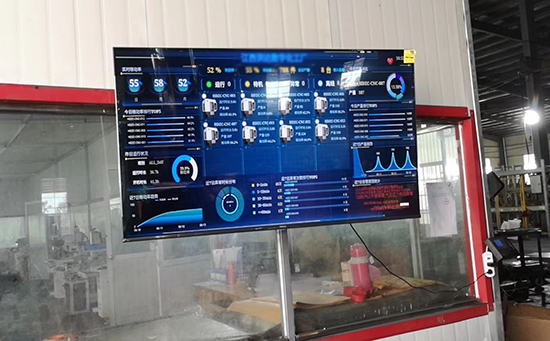
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬用戶實施案例,ERP 系統(tǒng)實現(xiàn)微信、銷售、庫存、生產(chǎn)、財務、人資、辦公等一體化管理
提取數(shù)字時,很多用戶在使用公式時會遇到結(jié)果不完整的問題,這種情況在數(shù)據(jù)處理、文本分析或自動化腳本執(zhí)行中比較常見。數(shù)字提取是一項重要的操作,尤其在處理大量數(shù)據(jù)或從文本中提取關鍵信息時,數(shù)字往往是最需要關注的部分。然而,如何準確、完整地提取數(shù)字并保證結(jié)果的準確性,依然是許多程序員和數(shù)據(jù)分析師面臨的一大挑戰(zhàn)。本文將詳細探討數(shù)字提取不完整的原因,并為解決這一問題提供一些思路與方法。
數(shù)字提取的常見方式
數(shù)字提取通常有多種方式,最常見的包括正則表達式、公式函數(shù)等。在數(shù)據(jù)表格和文本處理中,常常需要提取包含在字符串中的數(shù)字,這時可以通過編程語言的內(nèi)建函數(shù)或自定義的公式來實現(xiàn)。例如,Excel中的“提取數(shù)字”公式,Python中的正則表達式等。
在Excel中,用戶可以使用“=TEXTBETWEEN()”等函數(shù)結(jié)合字符串處理公式來提取數(shù)字。而在Python中,使用正則表達式(`re`模塊)可以非常靈活地從文本中匹配數(shù)字。在這些方式中,正則表達式是最強大的工具之一,它可以根據(jù)模式匹配提取數(shù)字,并且可以精確到提取整數(shù)、小數(shù)甚至科學計數(shù)法中的數(shù)字。
然而,無論是公式還是正則表達式,提取數(shù)字的操作在特定條件下可能會導致結(jié)果不完整,這就需要我們進一步探討其中的原因。
提取數(shù)字不完整的原因分析
1. 數(shù)字格式的多樣性
數(shù)字本身的格式非常多樣,包括整數(shù)、浮動小數(shù)、百分比、科學計數(shù)法、負數(shù)等。當提取公式或者正則表達式?jīng)]有針對所有可能的格式進行處理時,就可能導致提取結(jié)果的不完整。例如,如果公式只考慮了整數(shù)而沒有考慮到帶小數(shù)點的數(shù)字,就會錯過小數(shù)部分。
2. 字符串中的空格或特殊符號
在數(shù)據(jù)中,數(shù)字和其他字符之間可能存在空格、逗號、貨幣符號等,這些都可能影響數(shù)字提取的完整性。例如,數(shù)字“1,000”在某些情況下可能會被提取成“1”而不是“1000”。這種情況通常發(fā)生在沒有正確處理文本中的分隔符或符號的情況下。
3. 多次出現(xiàn)數(shù)字時的提取規(guī)則
當一個字符串中包含多個數(shù)字時,如果提取規(guī)則沒有指定是提取第一個數(shù)字、最后一個數(shù)字,還是所有數(shù)字,可能會導致提取結(jié)果的丟失或不完整。例如,如果一個公式僅提取了第一個出現(xiàn)的數(shù)字,后續(xù)的數(shù)字就會被忽略。
4. 程序處理邏輯的缺陷
在編程語言中,數(shù)字提取可能依賴于特定的算法或者函數(shù)。如果這些函數(shù)沒有經(jīng)過嚴格測試,或者其處理邏輯存在漏洞,那么就可能會導致提取結(jié)果的丟失或錯誤。例如,在使用正則表達式時,如果模式設計不合理,可能導致匹配不到某些數(shù)字格式,甚至無法提取到預期的內(nèi)容。
5. 數(shù)據(jù)中的噪聲或異常數(shù)據(jù)
數(shù)據(jù)中可能會存在噪聲或異常值,如亂碼、無關字符、特殊符號等。這些無關信息如果未被正確過濾,就會干擾數(shù)字的提取,導致結(jié)果的不完整。特別是在大數(shù)據(jù)環(huán)境下,噪聲數(shù)據(jù)更為復雜和多樣,處理起來更加困難。
解決數(shù)字提取不完整的策略
1. 增強數(shù)字提取公式的靈活性
在使用公式進行數(shù)字提取時,可以增強公式的容錯性。例如,在Excel中,使用`=VALUE()`函數(shù)將字符串轉(zhuǎn)化為數(shù)值,并配合`=TEXT()`函數(shù)進行格式控制,可以避免由于格式差異導致提取失敗的問題。而在Python中,可以通過正則表達式靈活定義匹配規(guī)則,確保不同格式的數(shù)字都能被提取出來。
2. 精確控制提取條件
在處理多個數(shù)字時,可以精確控制提取條件。例如,可以設置條件,只提取符合特定規(guī)則的數(shù)字,或者設置優(yōu)先級,按照數(shù)字出現(xiàn)的順序提取。在正則表達式中,使用不同的捕獲組(capturing groups)來提取多個數(shù)字,并確保每個數(shù)字都有獨立的處理邏輯。
3. 過濾空格和符號
為了避免空格或特殊符號的干擾,應該先對文本進行清理,去除不必要的符號。可以使用字符串處理函數(shù)(如`replace()`、`strip()`等)來刪除多余的字符。此外,正則表達式可以配置為跳過空格和非數(shù)字字符,只提取數(shù)字部分。
4. 完善數(shù)據(jù)清洗流程
在大數(shù)據(jù)環(huán)境下,數(shù)據(jù)清洗是一個關鍵步驟。通過增加噪聲過濾和異常值識別,可以有效避免因為噪聲數(shù)據(jù)而導致的提取錯誤。對于異常數(shù)據(jù),可以在提取之前先進行預處理,去除無關字符、亂碼和重復數(shù)據(jù),從而提高數(shù)字提取的準確性。
5. 測試和優(yōu)化提取規(guī)則
對提取規(guī)則進行嚴格的測試是非常重要的。可以通過對不同格式的數(shù)據(jù)進行多輪測試,找出可能存在的漏洞,并不斷優(yōu)化規(guī)則。對于正則表達式而言,應該根據(jù)數(shù)據(jù)的變化進行動態(tài)調(diào)整和優(yōu)化,確保其匹配能力強且精準。
總結(jié)
數(shù)字提取的完整性直接影響數(shù)據(jù)分析和處理的效果。造成提取結(jié)果不完整的原因包括數(shù)字格式的多樣性、字符串中的特殊符號、提取規(guī)則的缺陷、程序處理邏輯的問題以及數(shù)據(jù)中的噪聲。為了解決這一問題,我們可以通過增強公式靈活性、精確控制提取條件、過濾無關字符、完善數(shù)據(jù)清洗流程以及不斷優(yōu)化提取規(guī)則等手段,提高數(shù)字提取的準確性與完整性。數(shù)字提取不僅僅是一個技術問題,更是確保數(shù)據(jù)質(zhì)量的基礎,因此我們需要注重每一個環(huán)節(jié),以保證結(jié)果的準確和完整。