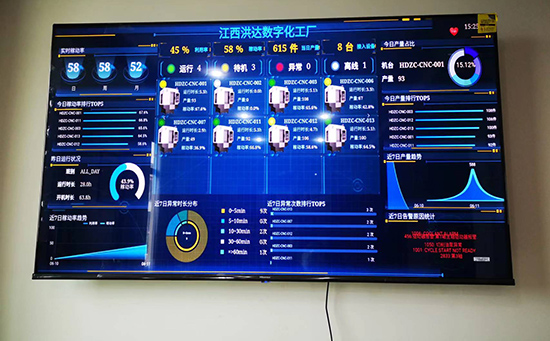
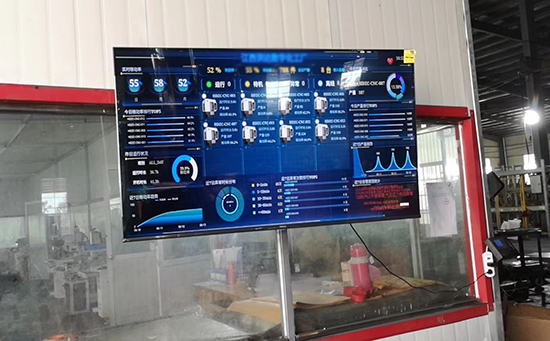
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬用戶實(shí)施案例,ERP 系統(tǒng)實(shí)現(xiàn)微信、銷售、庫存、生產(chǎn)、財(cái)務(wù)、人資、辦公等一體化管理
在現(xiàn)代編程和數(shù)據(jù)處理的領(lǐng)域,提取特定格式的信息是一個(gè)常見的需求,尤其是在處理字符串?dāng)?shù)據(jù)時(shí)。許多情況下,我們需要從一串字符中提取出符合某種規(guī)律的數(shù)字。例如,當(dāng)字符串的開頭是字母,而后面跟隨的是數(shù)字時(shí),我們?nèi)绾胃咝覝?zhǔn)確地提取這些數(shù)字呢?本文將詳細(xì)探討這一問題,并介紹如何通過各種編程語言和方法實(shí)現(xiàn)這一目標(biāo)。
了解基本問題和需求
首先,我們要明確問題的核心需求。假設(shè)有一系列字符串,其中包含字母和數(shù)字,且數(shù)字通常位于字母之后。我們的任務(wù)是從這些字符串中提取出緊隨字母后面的數(shù)字。這類問題在數(shù)據(jù)清洗、信息提取等場景中非常常見。例如,我們可能會(huì)處理含有“abc123”、“xyz456”等格式的數(shù)據(jù),而我們需要從中提取出“123”和“456”。
常見解決方案的概述
解決這個(gè)問題的方法有很多,不同的編程語言提供了不同的工具來處理字符串。在本文中,我們將著重介紹正則表達(dá)式和一些編程語言中的字符串處理方法。這些方法不僅簡單高效,而且能夠靈活應(yīng)對(duì)多種情況。
正則表達(dá)式的應(yīng)用
正則表達(dá)式是一種非常強(qiáng)大的文本處理工具,廣泛應(yīng)用于模式匹配、字符串提取等場景。在本問題中,我們可以通過正則表達(dá)式來提取字母后面的數(shù)字。
首先,我們需要設(shè)計(jì)一個(gè)合適的正則表達(dá)式模式。假設(shè)字符串的格式是字母和數(shù)字的組合,其中字母位于數(shù)字的前面。一個(gè)常見的正則表達(dá)式可以是“[a-zA-Z]+(\d+)”。這個(gè)表達(dá)式的含義如下:
– [a-zA-Z]+:匹配一個(gè)或多個(gè)字母(無論大小寫)。
– (\d+):匹配一個(gè)或多個(gè)數(shù)字,并將其捕獲。
使用這個(gè)正則表達(dá)式,我們可以從字符串中提取出緊隨字母后的數(shù)字部分。例如,在Python中,我們可以這樣實(shí)現(xiàn):
“`python
import re
示例字符串
text = “abc123 xyz456”
正則表達(dá)式匹配字母后面的數(shù)字
matches = re.findall(r'[a-zA-Z]+(\d+)’, text)
輸出結(jié)果
print(matches) 輸出: [‘123’, ‘456’]
“`
在這個(gè)例子中,`re.findall()`函數(shù)將返回一個(gè)列表,其中包含了從字符串中提取出來的所有數(shù)字部分。
不同編程語言中的字符串提取
除了正則表達(dá)式,許多編程語言也提供了其他字符串處理方法,可以幫助我們實(shí)現(xiàn)相同的功能。接下來,我們將簡要介紹幾種常見編程語言中的字符串提取方法。
Python中的字符串處理方法
Python是一種非常流行的編程語言,其內(nèi)置的字符串方法使得字符串處理非常方便。除了使用正則表達(dá)式外,我們還可以通過簡單的字符串操作來提取數(shù)字。以下是一個(gè)例子:
“`python
示例字符串
text = “abc123 xyz456”
提取數(shù)字
result = ”.join(filter(str.isdigit, text))
輸出結(jié)果
print(result) 輸出: 123456
“`
在這個(gè)例子中,我們通過`filter()`函數(shù)和`str.isdigit`方法過濾出字符串中的數(shù)字部分。雖然這種方法簡單,但它會(huì)提取出所有的數(shù)字,而不僅僅是字母后面的數(shù)字。因此,正則表達(dá)式在這種情況下更為精確。
JavaScript中的字符串處理方法
JavaScript作為前端開發(fā)的主流語言,也提供了豐富的字符串操作函數(shù)。利用正則表達(dá)式,我們可以在JavaScript中實(shí)現(xiàn)類似的數(shù)字提取功能。以下是一個(gè)示例:
“`javascript
let text = “abc123 xyz456”;
// 使用正則表達(dá)式提取數(shù)字
let matches = text.match(/[a-zA-Z]+(\d+)/g);
console.log(matches); // 輸出: [‘abc123’, ‘xyz456’]
“`
與Python類似,JavaScript的正則表達(dá)式功能強(qiáng)大,能夠在字符串中快速匹配字母后面的數(shù)字。
其他常用編程語言的實(shí)現(xiàn)
不同的編程語言都提供了不同的字符串操作工具。對(duì)于提取字母后面數(shù)字的需求,幾乎所有主流編程語言都能夠通過正則表達(dá)式來實(shí)現(xiàn)這一功能。對(duì)于那些不熟悉正則表達(dá)式的開發(fā)者來說,可以參考其他語言中內(nèi)置的字符串處理方法,或者通過第三方庫來實(shí)現(xiàn)。
在數(shù)據(jù)處理中應(yīng)用
在實(shí)際應(yīng)用中,字符串處理和數(shù)字提取是數(shù)據(jù)清洗過程中的重要環(huán)節(jié)。在許多數(shù)據(jù)集或日志文件中,我們經(jīng)常會(huì)遇到包含字母和數(shù)字的混合數(shù)據(jù)。通過正確地提取出數(shù)字,我們可以進(jìn)一步進(jìn)行數(shù)據(jù)分析、統(tǒng)計(jì)等操作。
例如,在處理電子商務(wù)網(wǎng)站的訂單號(hào)時(shí),我們可能會(huì)遇到類似“ORD12345”這樣的字符串。通過提取出數(shù)字部分,我們可以獲取到訂單的唯一標(biāo)識(shí)符。此外,數(shù)字提取的應(yīng)用還可以擴(kuò)展到時(shí)間戳、產(chǎn)品編號(hào)、用戶ID等多個(gè)方面。
總結(jié)
從字母后提取數(shù)字的任務(wù)在數(shù)據(jù)處理中非常常見。無論是使用正則表達(dá)式,還是通過編程語言內(nèi)置的字符串處理函數(shù),我們都能夠快速、準(zhǔn)確地實(shí)現(xiàn)這一功能。正則表達(dá)式提供了極其強(qiáng)大的模式匹配能力,可以幫助我們高效地從字符串中提取符合特定規(guī)則的數(shù)字。同時(shí),不同編程語言提供的字符串方法也是非常便捷的工具,幫助開發(fā)者在不同場景中靈活運(yùn)用。
總的來說,提取字母后面的數(shù)字是一個(gè)相對(duì)簡單但在數(shù)據(jù)處理中極為重要的任務(wù)。掌握不同的編程技巧和工具,可以大大提高工作效率,使得我們能夠快速解決實(shí)際問題。在實(shí)際開發(fā)中,選擇合適的工具和方法,不僅能幫助我們高效完成任務(wù),還能提升代碼的可維護(hù)性和可讀性。