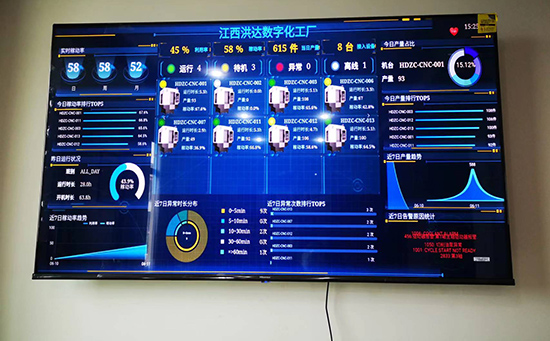
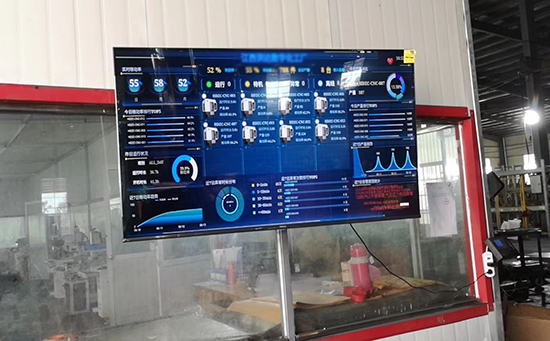
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬用戶實施案例,ERP 系統(tǒng)實現(xiàn)微信、銷售、庫存、生產(chǎn)、財務、人資、辦公等一體化管理
如何使用Excel打開PDF并提取數(shù)據(jù)
在日常辦公中,很多人需要從PDF文件中提取數(shù)據(jù),而這些數(shù)據(jù)可能需要進行進一步的分析或整理。為了提高工作效率,很多人選擇使用Excel進行數(shù)據(jù)處理。然而,Excel本身并不直接支持打開PDF文件,但通過一些技巧和工具,我們仍然能夠將PDF中的數(shù)據(jù)導入到Excel中。本文將為您詳細介紹如何使用Excel打開PDF文件并提取其中的數(shù)據(jù),幫助您簡化數(shù)據(jù)處理的過程。
利用Excel內置功能導入PDF數(shù)據(jù)
隨著Excel版本的更新,Microsoft加入了一個強大的內置功能,允許用戶直接將PDF文件中的表格數(shù)據(jù)導入到Excel中。這一功能在Excel 365和Excel 2021中尤其顯著,用戶可以輕松通過“獲取和轉換”功能從PDF中提取數(shù)據(jù)。以下是使用此功能的步驟:
1. 打開Excel并創(chuàng)建新工作簿:首先,打開Excel并創(chuàng)建一個新工作簿,準備將數(shù)據(jù)導入。
2. 選擇“數(shù)據(jù)”選項卡:在Excel的上方菜單中,點擊“數(shù)據(jù)”選項卡。
3. 點擊“從PDF獲取數(shù)據(jù)”:在“獲取和轉換數(shù)據(jù)”組中,選擇“從文件”下的“從PDF獲取數(shù)據(jù)”選項。
4. 選擇PDF文件:接下來,瀏覽文件夾并選擇您要提取數(shù)據(jù)的PDF文件。
5. 數(shù)據(jù)預覽與選擇:Excel會自動加載PDF中的內容并顯示一個預覽。您可以從中選擇包含數(shù)據(jù)的表格區(qū)域。
6. 加載數(shù)據(jù)到Excel:選中需要的數(shù)據(jù)后,點擊“加載”按鈕,Excel會將數(shù)據(jù)導入到工作簿中。
這種方法是處理簡單PDF文件中表格數(shù)據(jù)的最直接方式,適用于大多數(shù)情況下的數(shù)據(jù)提取需求。
使用第三方工具輔助提取PDF數(shù)據(jù)
盡管Excel內置功能可以有效地提取許多類型的PDF數(shù)據(jù),但并非所有PDF文件都能順利轉換,特別是那些格式復雜或者包含掃描內容的PDF文件。在這種情況下,第三方工具可以提供更多的靈活性和準確性。以下是一些常用的第三方工具,它們可以幫助用戶將PDF文件轉換為Excel文件或CSV文件,以便進一步處理。
1. Adobe Acrobat Pro DC:Adobe Acrobat Pro提供了一項強大的“導出PDF”功能,能夠將PDF文件直接轉換為Excel格式。用戶只需打開PDF文件,點擊“導出PDF”,選擇“電子表格”,然后選擇Excel格式。導出后,用戶可以在Excel中進一步處理數(shù)據(jù)。
2. PDF to Excel Converter:有許多在線工具和桌面應用程序可以將PDF文件轉換為Excel格式。例如,Smallpdf、ILovePDF和PDF2XL等工具可以幫助用戶提取PDF中的表格數(shù)據(jù)。這些工具的優(yōu)點是操作簡單,轉換過程通常比較快速,適用于沒有復雜數(shù)據(jù)結構的文件。
3. Tabula:Tabula是一個開源軟件,專門用于從掃描版PDF和包含表格內容的PDF中提取數(shù)據(jù)。它尤其適用于那些包含表格格式數(shù)據(jù)的PDF文件,能夠較為精準地識別和提取表格數(shù)據(jù)。
手動復制和粘貼數(shù)據(jù)
對于那些格式混亂或無法通過工具提取的PDF文件,有時手動復制和粘貼數(shù)據(jù)是一種解決方案。雖然這可能比較繁瑣,但在某些情況下,它是唯一可行的方式。您可以按照以下步驟操作:
1. 打開PDF文件:首先,打開您需要提取數(shù)據(jù)的PDF文件。
2. 選擇數(shù)據(jù)區(qū)域:使用鼠標選擇需要的文本或表格區(qū)域。如果是表格,您可能需要手動調整復制的區(qū)域,以確保數(shù)據(jù)不丟失。
3. 復制數(shù)據(jù):選擇數(shù)據(jù)后,右鍵點擊并選擇“復制”或使用快捷鍵“Ctrl+C”復制數(shù)據(jù)。
4. 粘貼到Excel:返回到Excel工作簿,選擇合適的單元格,使用“Ctrl+V”將數(shù)據(jù)粘貼到Excel中。
這種方法適用于較小的PDF文件,或者只有少量數(shù)據(jù)需要提取的情況,但對于大量數(shù)據(jù),手動操作的效率較低。
使用OCR技術提取掃描版PDF中的數(shù)據(jù)
如果您的PDF文件是掃描版的,Excel和一般的PDF提取工具可能無法直接讀取其中的文本和數(shù)據(jù)。這時候,OCR(光學字符識別)技術就顯得非常重要。OCR技術可以識別掃描圖像中的文本,并將其轉換為可編輯的內容。以下是如何使用OCR技術提取數(shù)據(jù)的步驟:
1. 使用OCR軟件:市場上有許多OCR軟件可供選擇,例如ABBYY FineReader、Adobe Acrobat Pro等。這些軟件可以掃描PDF文件中的圖像并識別其內容。
2. 轉換為Excel格式:通過OCR識別文本后,您可以將其轉換為Excel文件或CSV格式,方便進一步編輯。
3. 調整識別結果:由于OCR技術的識別準確性可能受到圖像質量的影響,因此在轉換后,您需要檢查并修正識別錯誤,確保數(shù)據(jù)的準確性。
OCR技術尤其適用于掃描文件或手寫內容的PDF文件,但需要注意的是,識別的準確性和文件質量密切相關。
總結
通過以上幾種方法,您可以根據(jù)不同的PDF類型和需求選擇最合適的方式,將PDF中的數(shù)據(jù)提取到Excel中。無論是使用Excel內置的導入功能,還是借助第三方工具、手動復制粘貼,或者通過OCR技術處理掃描文件,每種方法都有其適用場景。通過靈活應用這些技巧,您可以大大提高數(shù)據(jù)處理的效率,減少重復的工作量,從而更高效地完成任務。
在處理PDF文件時,最重要的是了解文件的類型和數(shù)據(jù)結構,選擇最適合的方法進行提取。隨著技術的不斷進步,未來的工具和功能可能會使數(shù)據(jù)提取變得更加自動化和智能化。