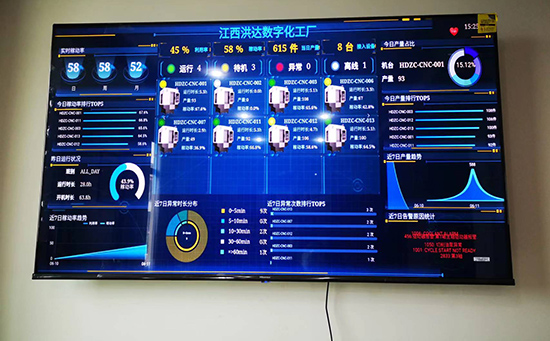
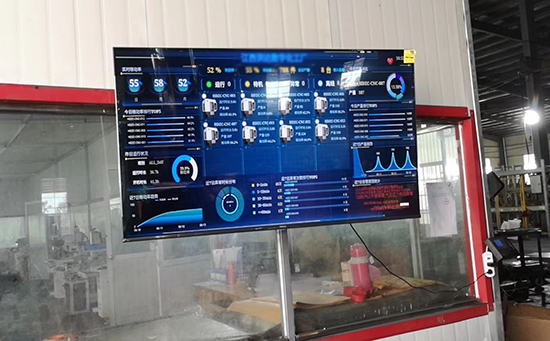
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬(wàn)用戶實(shí)施案例,ERP 系統(tǒng)實(shí)現(xiàn)微信、銷售、庫(kù)存、生產(chǎn)、財(cái)務(wù)、人資、辦公等一體化管理
如何在Python中調(diào)用Excel表格并計(jì)算求和結(jié)果
隨著數(shù)據(jù)分析需求的不斷增加,Python作為一種高效且靈活的編程語(yǔ)言,在數(shù)據(jù)處理和計(jì)算方面的應(yīng)用越來(lái)越廣泛。特別是在處理Excel文件時(shí),Python提供了豐富的庫(kù)和工具,幫助我們輕松地讀取、操作并分析數(shù)據(jù)。本文將深入探討如何在Python中調(diào)用Excel表格,并通過(guò)編程實(shí)現(xiàn)求和功能,幫助大家掌握這一常見(jiàn)的數(shù)據(jù)處理任務(wù)。
Python處理Excel文件的常用庫(kù)
在Python中,處理Excel文件的常用庫(kù)有`pandas`、`openpyxl`和`xlrd`。其中,`pandas`是最常用且功能強(qiáng)大的庫(kù)之一。它提供了簡(jiǎn)潔且高效的數(shù)據(jù)結(jié)構(gòu),可以直接讀取Excel文件中的數(shù)據(jù),并進(jìn)行復(fù)雜的計(jì)算和操作。
安裝必要的庫(kù)
首先,我們需要確保安裝了相關(guān)的庫(kù)。如果尚未安裝,可以使用以下命令進(jìn)行安裝:
“`bash
pip install pandas openpyxl
“`
這里我們選擇`pandas`和`openpyxl`,因?yàn)樗鼈冎С侄喾N格式的Excel文件(例如xlsx格式)。
讀取Excel文件
在實(shí)際操作中,首先需要將Excel表格的數(shù)據(jù)導(dǎo)入到Python環(huán)境中。`pandas`提供了非常簡(jiǎn)便的方式來(lái)讀取Excel文件。以下是如何讀取Excel文件的代碼示例:
“`python
import pandas as pd
讀取Excel文件
df = pd.read_excel(‘data.xlsx’)
顯示前幾行數(shù)據(jù)以便確認(rèn)
print(df.head())
“`
上述代碼中,`read_excel()`函數(shù)能夠直接讀取Excel文件并將其轉(zhuǎn)換為`pandas`的DataFrame格式。DataFrame是一個(gè)二維表格數(shù)據(jù)結(jié)構(gòu),類似于數(shù)據(jù)庫(kù)中的表格,可以通過(guò)列和行進(jìn)行訪問(wèn)和操作。
計(jì)算求和結(jié)果
假設(shè)我們有一個(gè)Excel文件,其中包含一列需要求和的數(shù)據(jù)。可以通過(guò)以下代碼計(jì)算該列的和:
“`python
假設(shè)我們要計(jì)算’銷售額’這一列的和
sum_sales = df[‘銷售額’].sum()
print(f’銷售額總和為:{sum_sales}’)
“`
在這個(gè)示例中,`df[‘銷售額’]`是訪問(wèn)Excel表格中“銷售額”列的數(shù)據(jù),而`.sum()`方法則會(huì)計(jì)算該列所有數(shù)值的總和。`sum()`是`pandas`中提供的一個(gè)非常實(shí)用的方法,支持直接對(duì)數(shù)值型數(shù)據(jù)進(jìn)行求和。
處理Excel中的多個(gè)工作表
如果Excel文件包含多個(gè)工作表,`pandas`也能輕松處理。我們可以指定工作表的名稱或索引來(lái)讀取指定的工作表。以下是讀取多個(gè)工作表的代碼示例:
“`python
讀取指定工作表
df_sheet1 = pd.read_excel(‘data.xlsx’, sheet_name=’Sheet1′)
df_sheet2 = pd.read_excel(‘data.xlsx’, sheet_name=’Sheet2′)
查看Sheet1的數(shù)據(jù)
print(df_sheet1.head())
“`
此外,還可以通過(guò)`sheet_name=None`一次性讀取Excel文件中的所有工作表,并返回一個(gè)字典,其中每個(gè)工作表對(duì)應(yīng)一個(gè)DataFrame:
“`python
讀取所有工作表
all_sheets = pd.read_excel(‘data.xlsx’, sheet_name=None)
查看所有工作表的名稱
print(all_sheets.keys())
“`
數(shù)據(jù)清洗和過(guò)濾
在處理Excel文件中的數(shù)據(jù)時(shí),經(jīng)常會(huì)遇到缺失值、異常值或格式不一致的情況。`pandas`提供了豐富的數(shù)據(jù)清洗和處理功能。以下是如何清洗數(shù)據(jù)和進(jìn)行求和計(jì)算的示例:
“`python
刪除缺失值
df_cleaned = df.dropna(subset=[‘銷售額’])
過(guò)濾銷售額大于1000的數(shù)據(jù)
df_filtered = df[df[‘銷售額’] > 1000]
計(jì)算過(guò)濾后的銷售額總和
sum_sales_filtered = df_filtered[‘銷售額’].sum()
print(f’過(guò)濾后的銷售額總和為:{sum_sales_filtered}’)
“`
在上述代碼中,我們使用了`dropna()`方法刪除了“銷售額”列中存在缺失值的行,并使用條件過(guò)濾對(duì)數(shù)據(jù)進(jìn)行篩選。最后,計(jì)算了篩選后的“銷售額”總和。
保存計(jì)算結(jié)果
在完成數(shù)據(jù)處理和計(jì)算后,往往需要將結(jié)果保存為新的Excel文件或CSV文件。以下是將計(jì)算結(jié)果保存為Excel文件的代碼示例:
“`python
將計(jì)算結(jié)果保存到新的Excel文件
df_filtered.to_excel(‘filtered_data.xlsx’, index=False)
“`
`to_excel()`方法可以將DataFrame數(shù)據(jù)保存為Excel格式,`index=False`表示不保存行索引。
總結(jié)
在本文中,我們深入探討了如何在Python中調(diào)用并計(jì)算Excel表格的求和結(jié)果。通過(guò)使用`pandas`庫(kù),我們能夠輕松地讀取Excel文件、清洗數(shù)據(jù)、進(jìn)行計(jì)算并保存結(jié)果。無(wú)論是在數(shù)據(jù)分析、財(cái)務(wù)報(bào)表還是業(yè)務(wù)決策中,Python的Excel處理能力都能大大提高工作效率,節(jié)省大量時(shí)間。
掌握Python中對(duì)Excel文件的操作和數(shù)據(jù)處理技能,能夠?yàn)槲覀兲峁└鼜?qiáng)大的數(shù)據(jù)分析能力,幫助我們應(yīng)對(duì)日常工作中的各種數(shù)據(jù)處理任務(wù)。通過(guò)不斷練習(xí)和探索,我們可以更好地理解并運(yùn)用Python的強(qiáng)大功能,提升數(shù)據(jù)分析的效率和準(zhǔn)確性。