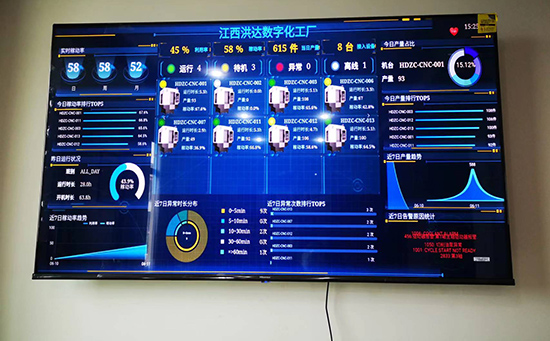
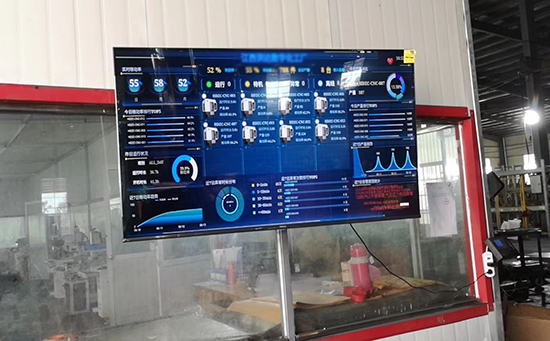
ERP系統(tǒng) & MES 生產(chǎn)管理系統(tǒng)
10萬用戶實施案例,ERP 系統(tǒng)實現(xiàn)微信、銷售、庫存、生產(chǎn)、財務、人資、辦公等一體化管理
一次性定值的概念與應用
在編程和數(shù)據(jù)分析中,隨機數(shù)的生成常常扮演著重要的角色。通過函數(shù)如 RAND 可以生成偽隨機數(shù),這些數(shù)值常常用于模擬、測試和算法開發(fā)等場景。然而,在某些情況下,我們希望能夠使生成的隨機數(shù)保持一致,確保結(jié)果的可復現(xiàn)性。在這種背景下,“一次性定值”的概念應運而生。通過設置定值機制,我們能夠在多次運行中獲取相同的隨機值,從而確保實驗結(jié)果的穩(wěn)定性和準確性。
RAND函數(shù)的基本原理
RAND 是一個常見的隨機數(shù)生成函數(shù),廣泛應用于不同編程語言和工具中。它通過算法生成一個均勻分布的隨機數(shù),通常在0到1之間。在數(shù)據(jù)分析和模型訓練中,RAND 函數(shù)的作用不可小覷,因為它能夠為模型帶來隨機性,避免因數(shù)據(jù)重復性導致的偏差。不同的編程語言對 RAND 函數(shù)的實現(xiàn)可能略有不同,但本質(zhì)上它們都遵循相似的隨機數(shù)生成原理。
一次性定值的需求與目的
在許多實際應用場景中,我們希望能重復進行某項操作并得到相同的結(jié)果。例如,進行模型訓練時,我們希望每次運行代碼時生成的隨機數(shù)據(jù)集是相同的,以便進行對比實驗或復現(xiàn)實驗過程。為了滿足這一需求,我們引入了一次性定值的概念。通過設定固定的隨機種子(seed),可以確保每次生成的隨機數(shù)序列一致,避免了由于隨機性帶來的差異性,保證了實驗的可重復性。
如何在不同編程語言中實現(xiàn)一次性定值
實現(xiàn)一次性定值的核心方法是設置“隨機種子”。不同編程語言提供了不同的方式來設置種子,以下是幾種常見編程語言的示例。
1. Python
在Python中,使用 `random.seed()` 可以設置隨機種子。通過設定一個固定的種子值,每次調(diào)用 `random` 模塊中的隨機數(shù)生成函數(shù)時,都會生成相同的隨機數(shù)序列。例如:
“`python
import random
random.seed(42) 設定隨機種子
print(random.random()) 生成一個隨機數(shù)
“`
每次運行該代碼,生成的隨機數(shù)將始終一致。
2. C++
在C++中,設置隨機數(shù)種子通常使用 `srand()` 函數(shù)。它接受一個整數(shù)作為參數(shù),這個整數(shù)通常來源于時間戳或一個固定的值。例子如下:
“`cpp
include
include
include
int main() {
srand(42); // 設置隨機種子為42
std::cout << rand() % 100 << std::endl; // 輸出一個隨機數(shù)
return 0;
}
“`
這樣,每次運行時生成的隨機數(shù)都會相同。
3. MATLAB
在MATLAB中,使用 `rng()` 函數(shù)來設置隨機數(shù)生成器的種子,確保隨機數(shù)序列的一致性。例如:
“`matlab
rng(42); % 設置隨機數(shù)種子為42
disp(rand()); % 輸出一個隨機數(shù)
“`
設置了種子之后,每次生成的隨機數(shù)將保持一致。
一次性定值在數(shù)據(jù)分析中的重要性
一次性定值在數(shù)據(jù)分析中的重要性不可忽視,尤其是在以下幾個方面:
1. 實驗復現(xiàn)性
在數(shù)據(jù)科學領(lǐng)域,實驗的復現(xiàn)性是至關(guān)重要的。一次性定值確保每次執(zhí)行相同的代碼和操作時,結(jié)果是可以重現(xiàn)的。這對于驗證算法的效果、調(diào)整模型參數(shù)、對比不同方法的優(yōu)劣等方面都是非常重要的。
2. 結(jié)果穩(wěn)定性
通過設置定值,我們可以避免由于每次生成的隨機數(shù)不同所帶來的結(jié)果波動。例如,在機器學習模型中,隨機數(shù)據(jù)的劃分可能會影響模型的訓練效果。設置種子后,隨機數(shù)據(jù)集的劃分就會保持一致,從而避免了每次訓練時因數(shù)據(jù)變化導致的結(jié)果不穩(wěn)定。
3. 調(diào)試和優(yōu)化
在調(diào)試和優(yōu)化算法時,保持一致的輸入數(shù)據(jù)是非常重要的。一次性定值可以確保調(diào)試過程中每次運行代碼時使用相同的測試數(shù)據(jù),從而更容易識別和修復問題。
一次性定值在機器學習中的應用
在機器學習中,數(shù)據(jù)的隨機劃分、初始化權(quán)重以及交叉驗證等過程都依賴于隨機數(shù)的生成。如果每次運行時生成的隨機數(shù)不同,模型的訓練結(jié)果可能會出現(xiàn)較大波動。為了避免這種情況,設置隨機種子成為了機器學習工程中的常見做法。
1. 數(shù)據(jù)劃分
在數(shù)據(jù)預處理過程中,我們通常將數(shù)據(jù)集隨機劃分為訓練集和測試集。為了保證實驗的公平性和結(jié)果的對比性,設置種子可以使得每次劃分的訓練集和測試集都相同,確保模型的表現(xiàn)不受數(shù)據(jù)劃分的影響。
2. 模型初始化
許多機器學習模型(例如神經(jīng)網(wǎng)絡)會在訓練開始時隨機初始化權(quán)重。如果初始化的權(quán)重每次都不同,模型的訓練過程可能會出現(xiàn)差異,影響最終的模型效果。通過設定固定的種子,可以確保每次初始化權(quán)重時都是相同的,從而保證模型訓練的一致性。
3. 交叉驗證
交叉驗證是一種評估模型性能的常見方法,它通過將數(shù)據(jù)集劃分為多個子集,進行多次訓練和驗證。在交叉驗證中,設置隨機種子可以確保每次訓練時劃分的數(shù)據(jù)集是一致的,避免了數(shù)據(jù)劃分差異對評估結(jié)果的影響。
一次性定值的局限性
雖然一次性定值可以確保結(jié)果的一致性,但它也存在一些局限性:
1. 缺乏多樣性
設置固定的隨機種子可能導致模型對數(shù)據(jù)的敏感性降低,影響模型的泛化能力。在某些情況下,我們需要保證模型能夠適應不同的數(shù)據(jù)變動,而一次性定值可能導致模型對特定數(shù)據(jù)過于依賴,失去隨機性帶來的優(yōu)勢。
2. 無法模擬真實環(huán)境
在現(xiàn)實世界中,隨機性和不確定性是常態(tài),完全依賴固定的隨機種子可能導致實驗結(jié)果與實際情況不符。因此,在一些實際應用中,我們可能需要允許一定程度的隨機性,而不是嚴格固定每個實驗的輸入數(shù)據(jù)。
總結(jié)歸納
一次性定值作為一種重要的技術(shù)手段,通過設置隨機種子來確保每次生成的隨機數(shù)序列一致,進而保證實驗的可復現(xiàn)性和結(jié)果的穩(wěn)定性。它在數(shù)據(jù)分析、機器學習和算法開發(fā)中具有廣泛的應用價值,尤其是在實驗復現(xiàn)性、調(diào)試、優(yōu)化和模型評估等方面。然而,我們也要意識到它的局限性,特別是在需要多樣性和適應真實環(huán)境的情況下。因此,在實際應用中,需要根據(jù)具體需求合理使用一次性定值技術(shù),確保結(jié)果的可靠性和模型的泛化能力。